Accessing HCA Data and Metadata
This section briefly reviews how to find and download cross-project data and associated metadata using the Data Browser and curl commands.
Finding Data
The Datasets section of the Data Portal provides an interactive Data Explorer. You can design a unique cohort, or data subset, by selecting various facets in the Data Explorer's Filters on the left side of the page.
The Samples tab shows you have many samples have been selected, while the Files tab shows you how many files have been selected.
Preparing Data for Export
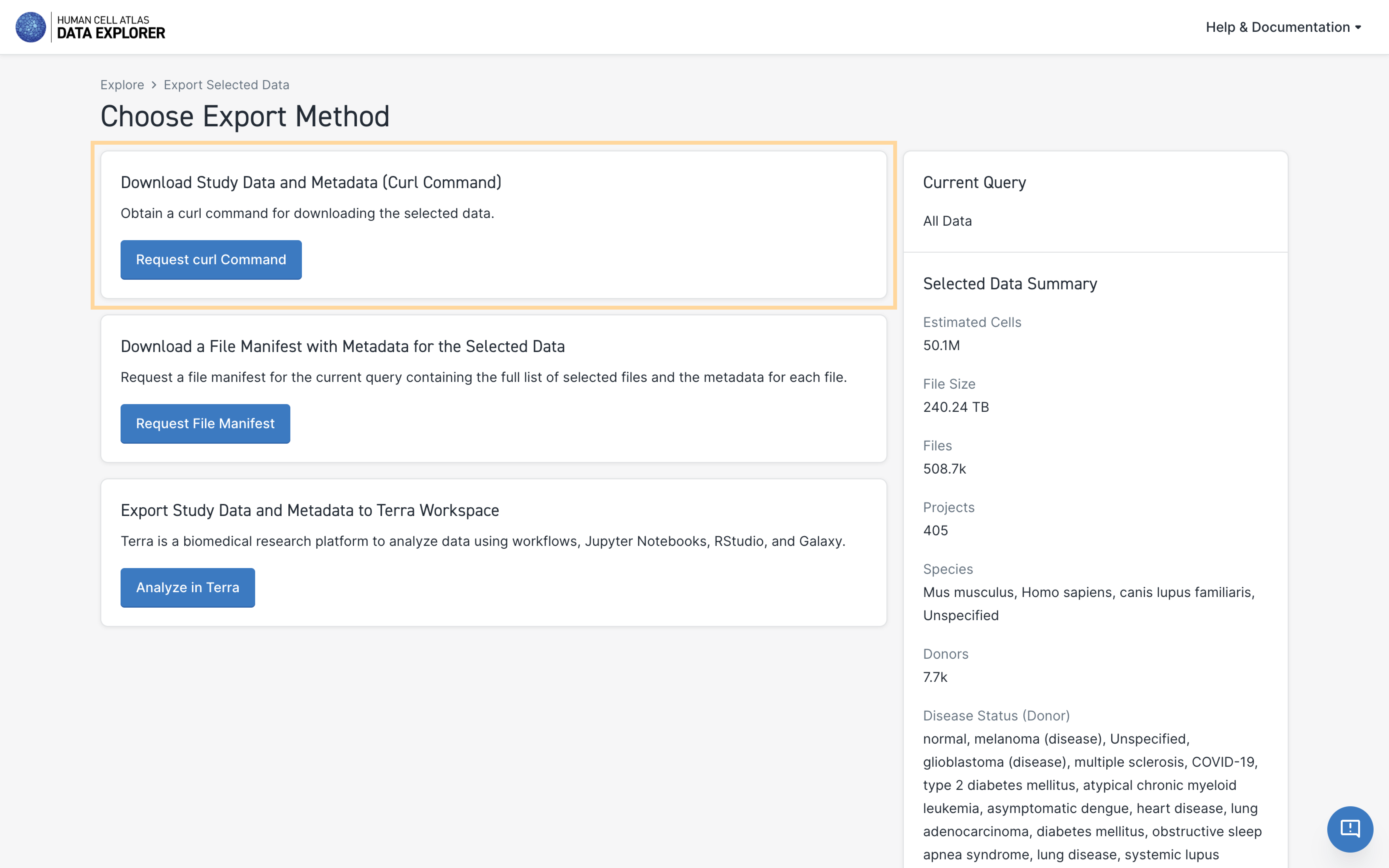
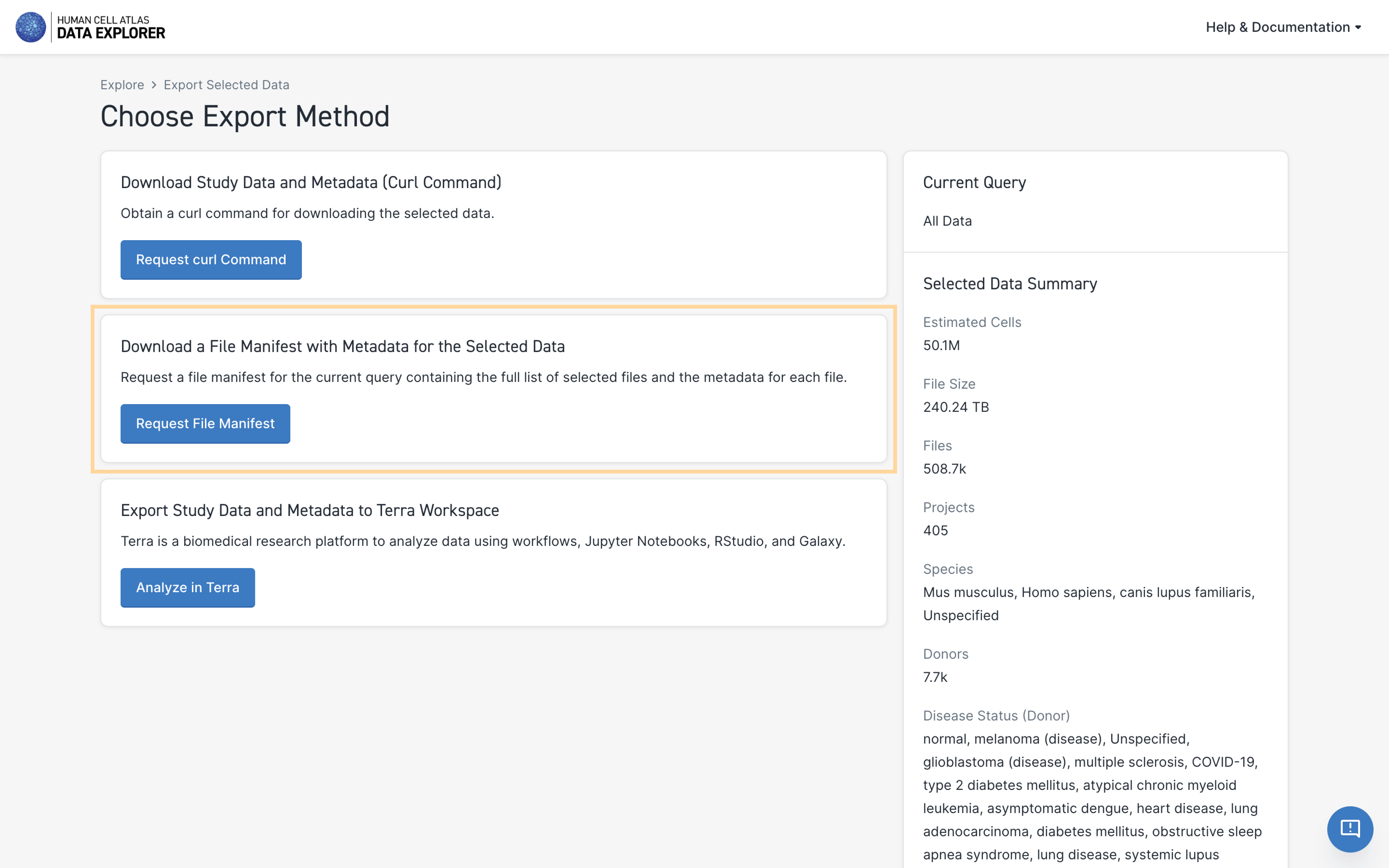
After you identify a cohort of interest, you can download the raw data, analysis files, and metadata by clicking Export on the top right of the page.
![]()
This will open a new page giving you the option to:
- Download Study Data and Metadata (Curl Command)
- Download a File Manifest with Metadata for the Selected Data
- Export Study Data and Metadata to a Terra Workspace
Downloading Data with a Curl Command
To download the raw and processed data:
- Under Download Study Data and Metadata (Curl Command), select Request curl Command
- Select the files to include in the download—the download dialog box gives you the option to further refine the types of files
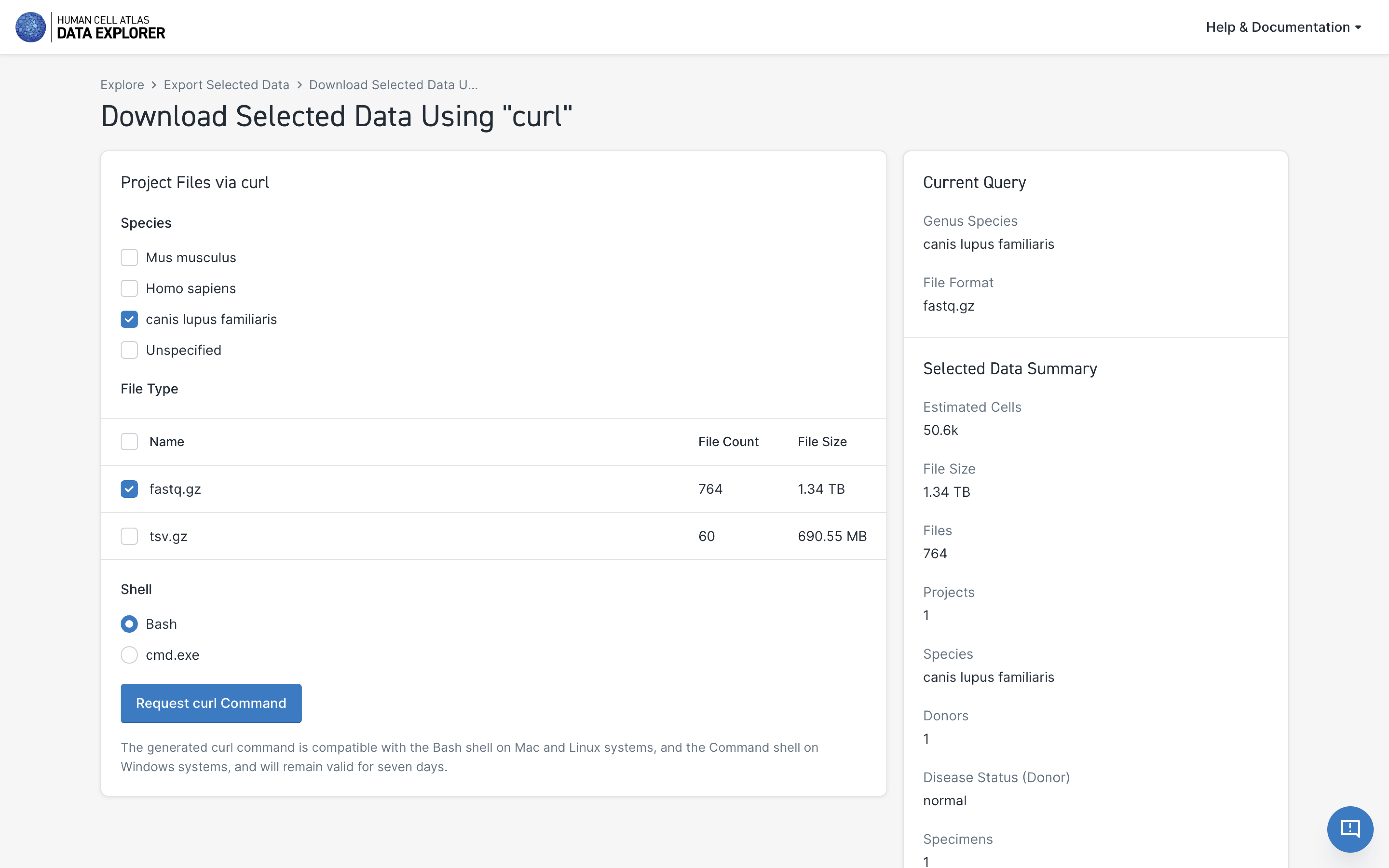
- Select Request curl Command
After a few seconds, a new window with a curl command will open.
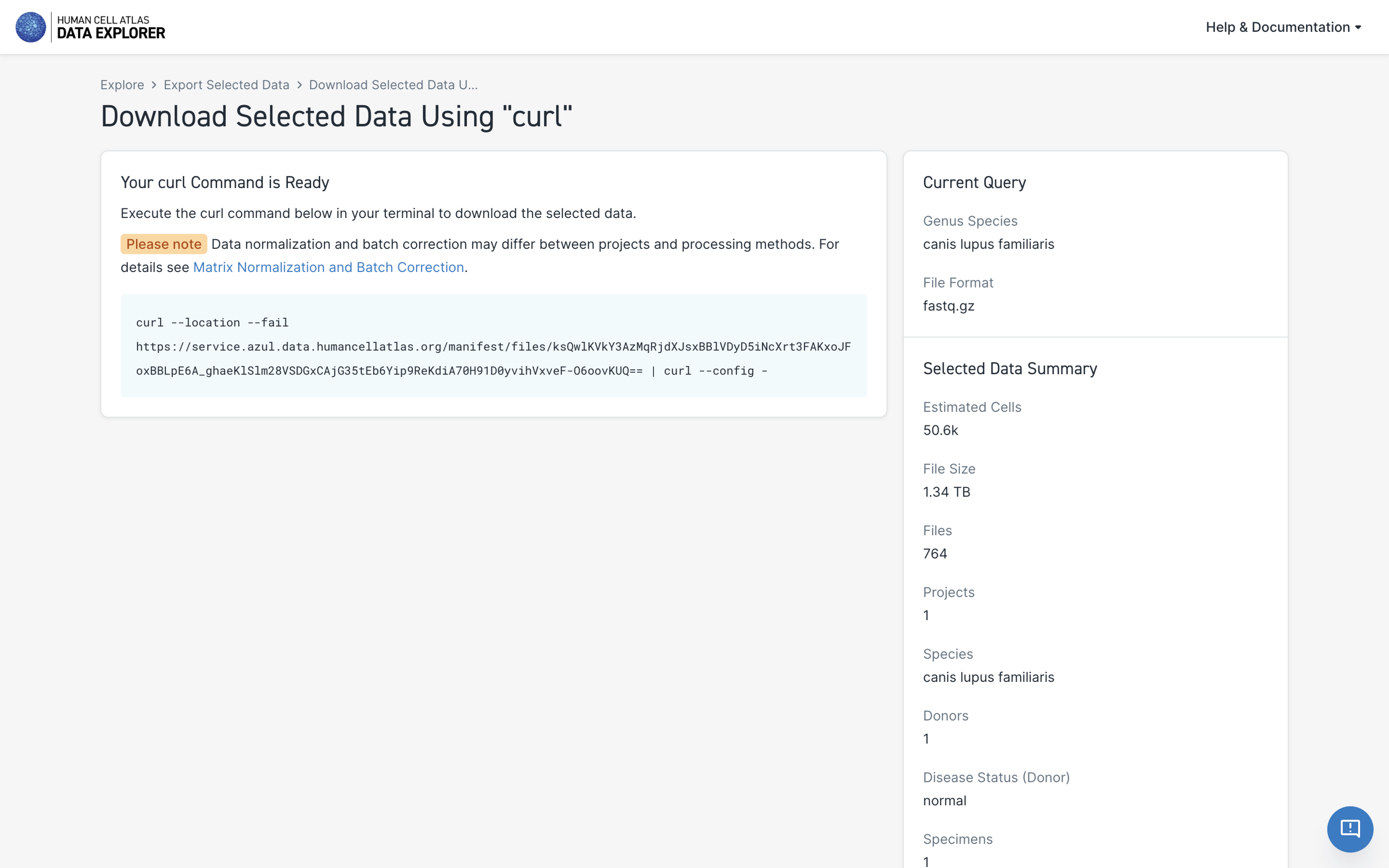 Paste this curl command in your local or cloud-based terminal to download the data.
Paste this curl command in your local or cloud-based terminal to download the data.
After downloading the data files, return to the Export Selected Data page using the page breadcrumbs to download the metadata (see step-by-step instructions below).
Downloading Metadata in a Data Manifest
Once you have downloaded the selected data files, you can download all the metadata associated with the cross-project data files.
This metadata, also called a "Data Manifest" is in TSV file format and lists all the details about your selected data such as donor information and disease-state; however, the manifest is not the actual data file itself.
To download the metadata from the Export Selected Data page:
- Under Download a File Manifest with Metadata for the Selected Data, select Request File Manifest
- Select the file types to include in the manifest; the default selection will be the same as what you selected for the data download
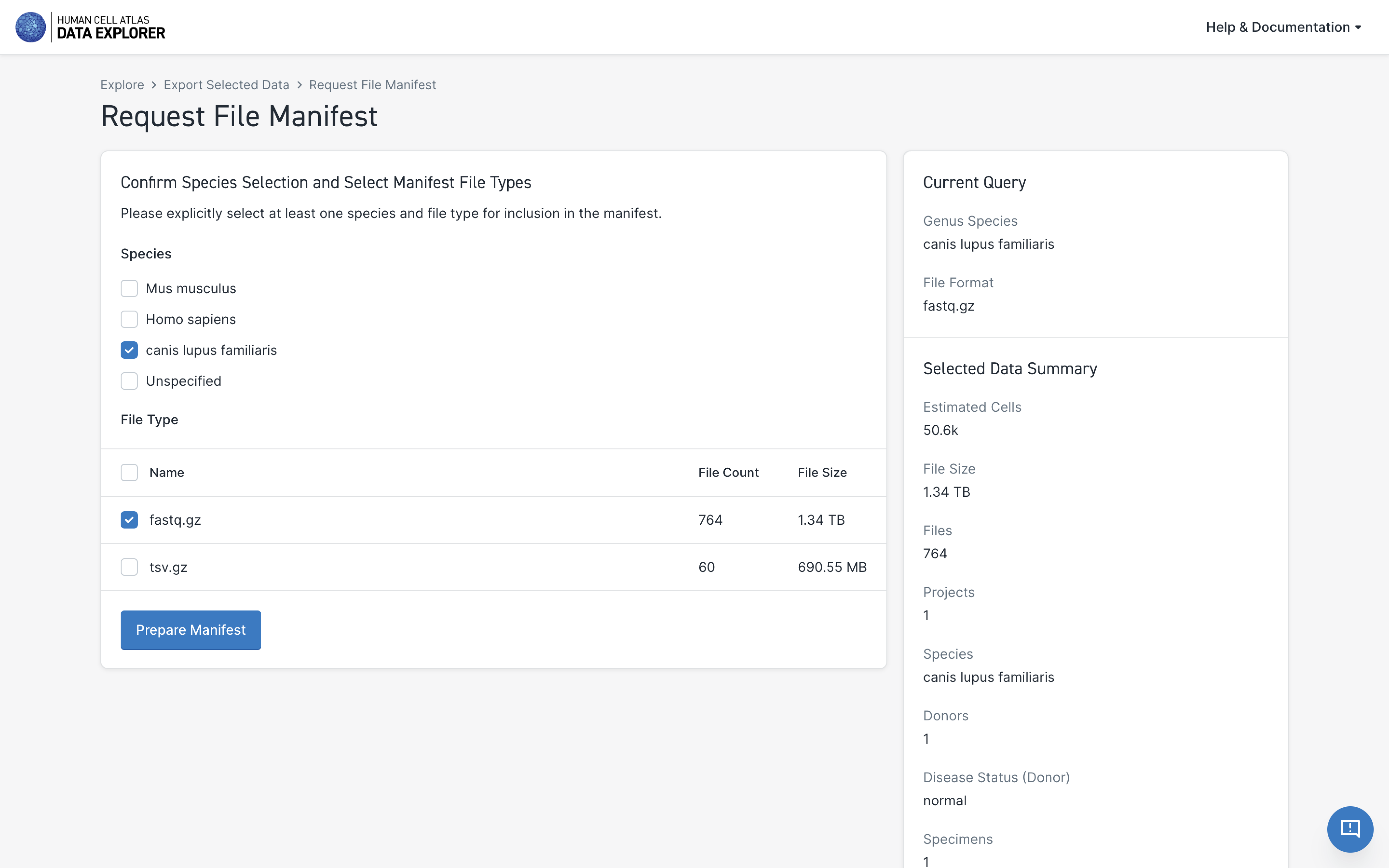
- Select Prepare Manifest
When selecting file types for the metadata manifest, note that the listed File Sizes are for the actual data files and not for the manifest itself.
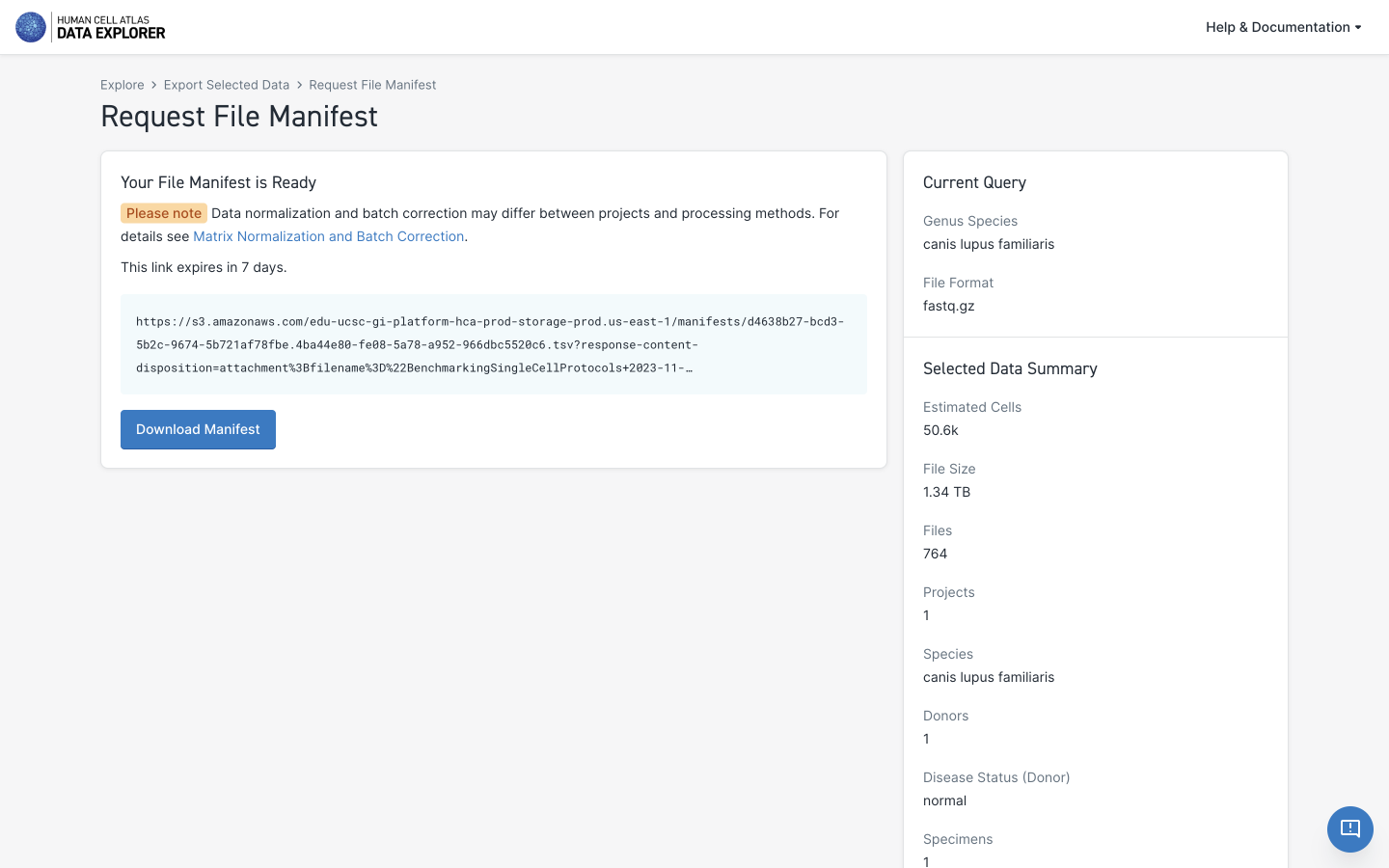 The format of the manifest file (TSV) is a simple tab-separated text file, with the first line representing the header title for each column. It is OK to remove rows for unwanted files but the header row must remain, and the columns should remain the same.
The format of the manifest file (TSV) is a simple tab-separated text file, with the first line representing the header title for each column. It is OK to remove rows for unwanted files but the header row must remain, and the columns should remain the same.